Hacking on Clang is surprisingly easy



Date: 2020-01-27
Git: https://gitlab.com/mort96/blog/blob/published/content/00000-home/00012-clang-compiler-hacking.md
I happen to think that the current lambda syntax for C++ is kind of verbose. I'm not the only one to have thought that, and there has already been a paper discussing a possible abbreviated lambda syntax (though it was rejected).
In this blog post, I will detail my attempt to implement a sort of simplest possible version of an abbreviated lambda syntax. Basically, this:
[](auto &&a, auto &&b) => a.id() < b.id();
should mean precisely:
[](auto &&a, auto &&b) { return a.id() < b.id(); };
I will leave a discussion about whether that change is worth it or not to the end. Most of this article will just assume that we want that new syntax, and discuss how to actually implement it in Clang.
If you want to read more discussion on the topic, I wrote a somewhat controversial post on Reddit discussing why I think it might be a good idea.
Here's the implementation I will go through in this post: https://github.com/mortie/llvm/commit/e4726dc9d9d966978714fc3d85c6e9c335a38ab8 - 28 additions, including comments and whitespace, across 3 files.
Getting the Clang code
This wasn't my first time compiling Clang, but it was my first time downloading the source code with the intent to change it.
LLVM has a nice page which details getting and building Clang, but the tl;dr is:
git clone https://github.com/llvm/llvm-project.git
cd llvm-project && mkdir build && cd build
cmake -DCMAKE_INSTALL_PREFIX=`pwd`/inst -DLLVM_ENABLE_PROJECTS=clang -DCMAKE_BUILD_TYPE=Release ../llvm
make -j 8
make install
A few points to note:
- The build will take a long time. Clang is big.
- I prefer
-DCMAKE_BUILD_TYPE=Releasebecause it's way faster to build. Linking Clang with debug symbols and everything takes ages and will OOM your machine. - This will install your built clang to
inst(short for "install"). The clang binary itself will be ininst/bin/clang.
Now that we have a clang setup, we can have a look at how the project is laid out, and play with it.
Changing the Clang code
The feature I want to add is very simple: Basically, I want [] => 10 to mean
the exact same thing as [] { return 10; }. In order to understand how one
would achieve that, an extremely short introduction to how compilers work
is necessary:
Our code is just a sequence of bytes, like [] => 10 + 20. In order for Clang to
make sense of that, it will go through many steps. We can basically divide
a compiler into two parts: the "front-end", which goes through many steps to
build a thorough understanding of the code as a
tree structure, and the "back-end"
which goes through many steps to remove information, eventually ending up with
a simple series of bytes again, but this time as machine code instead of ASCII.
We'll ignore the back-end for now. The front-end basically works like this:
- Split the stream of bytes into a stream of tokens. This step turns
[] => 10 + 20into something like(open-bracket) (close-bracket) (fat-arrow) (number: 10) (plus) (number: 20). - Go through those tokens and construct a tree. This step turns the sequence of tokens
into a tree:
(lambda-expression (body (return-statement (add-expression (number 10) (number 20)))))(Yeah, this looks a lot like Lisp. There's a reason people say Lisp basically has no syntax; you're just writing out the syntax tree by hand.) - Add semantic information, such as types.
The first phase is usually called lexical analysis, or tokenization, or scanning. The second phase is what we call parsing. The third phase is usually called semantic analysis or type checking.
Well, the change I want to make involves adding a new token, the "fat arrow" token =>.
That means we'll have to find out how the lexer (or tokenizer) is implemented;
where it keeps its list of valid tokens types, and where it turns the input text
into tokens.
After some grepping, I found the file
clang/include/clang/Basic/TokenKinds.def,
which includes a bunch of token descriptions, such as
PUNCTUATOR(arrow, "->"). This file seems to be a
"supermacro";
a file which exists to be included by another file as a form of macro expansion.
I added PUNCTUATOR(fatarrow, "=>") right below the PUNCTUATOR(arrow, "->") line.
Now that we have defined our token, we need to get the lexer to actually generate it.
After some more grepping, I found
clang/lib/Lex/Lexer.cpp,
where the Lexer::LexTokenInternal function is what's actually looking at
characters and deciding what tokens they represent. It has a case statement
to deal with tokens which start with an = character:
case '=':
Char = getCharAndSize(CurPtr, SizeTmp);
if (Char == '=') {
// If this is '====' and we're in a conflict marker, ignore it.
if (CurPtr[1] == '=' && HandleEndOfConflictMarker(CurPtr-1))
goto LexNextToken;
Kind = tok::equalequal;
CurPtr = ConsumeChar(CurPtr, SizeTmp, Result);
} else {
Kind = tok::equal;
}
break;
Given that, the change to support my fatarrow token is really simple:
case '=':
Char = getCharAndSize(CurPtr, SizeTmp);
if (Char == '=') {
// If this is '====' and we're in a conflict marker, ignore it.
if (CurPtr[1] == '=' && HandleEndOfConflictMarker(CurPtr-1))
goto LexNextToken;
Kind = tok::equalequal;
CurPtr = ConsumeChar(CurPtr, SizeTmp, Result);
// If the first character is a '=', and it's followed by a '>', it's a fat arrow
} else if (Char == '>') {
Kind = tok::fatarrow;
CurPtr = ConsumeChar(CurPtr, SizeTmp, Result);
} else {
Kind = tok::equal;
}
break;
Now that we have a lexer which generates a tok::fatarrow any time it encounters
a => in our code, we can start changing the parser to make use of it.
Since I want to change lambda parsing, the code which parses a lamba seems like
a good place to start (duh). I found that in a file called
clang/lib/Parse/ParseExprCXX.cpp,
in the function ParseLambdaExpressionAfterIntroducer. Most of the function deals
with things like the template parameter list and trailing return type,
which I don't want to change, but the very end of the function contains this gem:
// Parse compound-statement.
if (!Tok.is(tok::l_brace)) {
Diag(Tok, diag::err_expected_lambda_body);
Actions.ActOnLambdaError(LambdaBeginLoc, getCurScope());
return ExprError();
}
StmtResult Stmt(ParseCompoundStatementBody());
BodyScope.Exit();
TemplateParamScope.Exit();
if (!Stmt.isInvalid() && !TrailingReturnType.isInvalid())
return Actions.ActOnLambdaExpr(LambdaBeginLoc, Stmt.get(), getCurScope());
Actions.ActOnLambdaError(LambdaBeginLoc, getCurScope());
return ExprError();
- If the next token isn't an opening brace, error.
- Parse a compound statement body (i.e consume a
{, read statements until the}). - After some housekeeping, act on the now fully parsed lambda expression.
In principle, what we want to do is to check if the next token is a => instead
of a {; if it is, we want to parse an expression instead of a compound statement,
and then somehow pretend that the expression is a return statement.
Through some trial, error and careful copy/pasting, I came up with this block
of code which I put right before the if (!Tok.is(tok::l_brace)):
// If this is an arrow lambda, we just need to parse an expression.
// We parse the expression, then put that expression in a return statement,
// and use that return statement as our body.
if (Tok.is(tok::fatarrow)) {
SourceLocation ReturnLoc(ConsumeToken());
ExprResult Expr(ParseExpression());
if (Expr.isInvalid()) {
Actions.ActOnLambdaError(LambdaBeginLoc, getCurScope());
return ExprError();
}
StmtResult Stmt = Actions.ActOnReturnStmt(ReturnLoc, Expr.get(), getCurScope());
BodyScope.Exit();
TemplateParamScope.Exit();
if (!Stmt.isInvalid() && !TrailingReturnType.isInvalid())
return Actions.ActOnLambdaExpr(LambdaBeginLoc, Stmt.get(), getCurScope());
Actions.ActOnLambdaError(LambdaBeginLoc, getCurScope());
return ExprError();
}
// Otherwise, just parse a compound statement as usual.
if (!Tok.is(tok::l_brace)) ...
This is really basic; if the token is a => instead of a {, parse an expression,
then put that expression into a return statement, and then use that return statement
as our lambda's body.
And it works! Lambda expressions with fat arrows are now successfully parsed as if they were regular lambdas whose body is a single return statement:
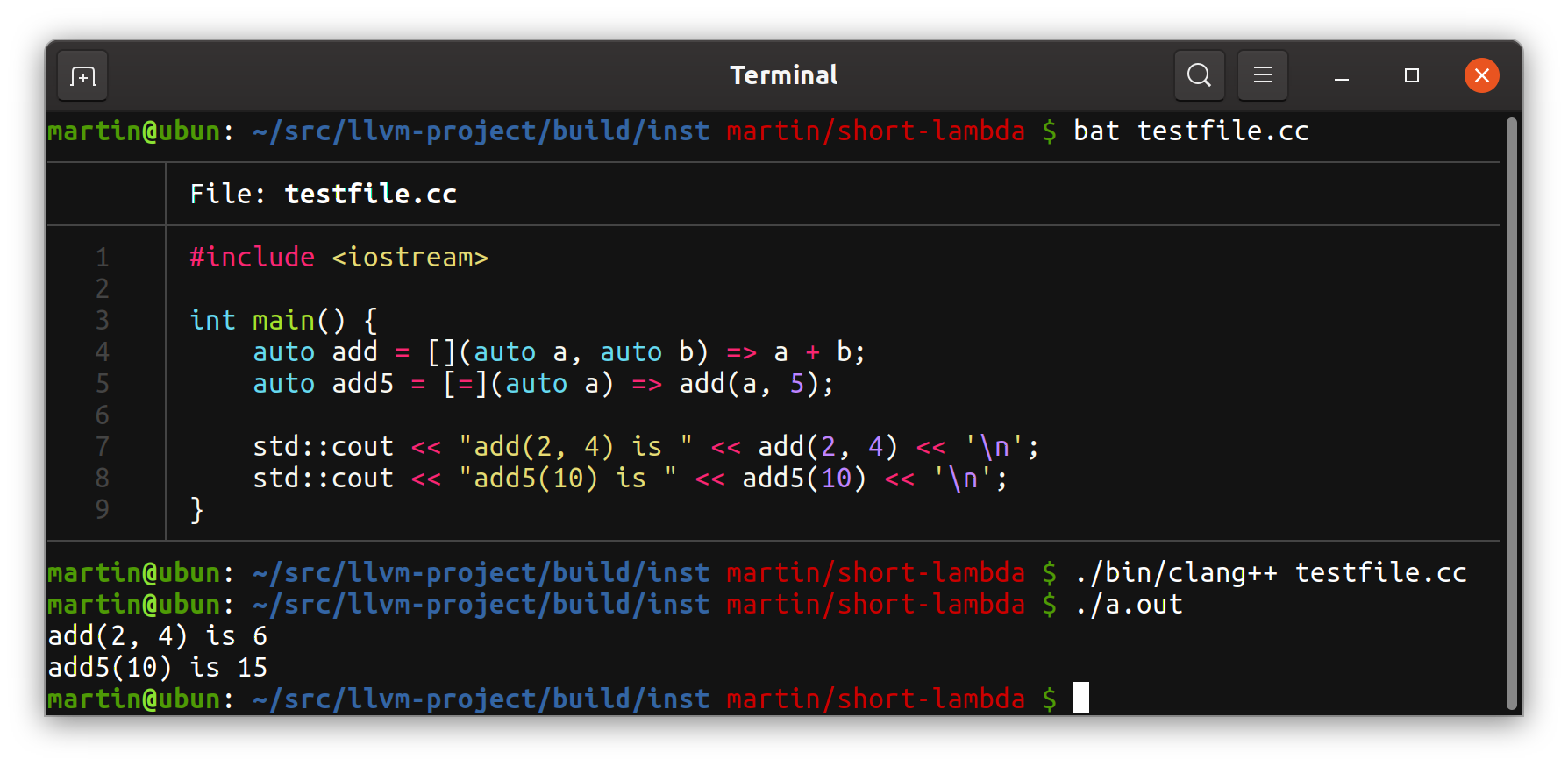
Was it worth it?
Implementing this feature into Clang was definitely worth it just to get more familiar with how the code base works. However, is the feature itself a good idea at all?
I think the best way to decide if a new syntax is better or not is to look at old code which could've made use of the new syntax, and decide if the new syntax makes a big difference. Therefore, and now that I have a working compiler, I have gone through all the single-expression lambdas and replaced them with my fancy new arrow lambdas in some projects I'm working on.
Before:
std::erase_if(active_chunks_, [](Chunk *chunk) { return !chunk->isActive(); });
After:
std::erase_if(active_chunks_, [](Chunk *chunk) => !chunk->isActive());
This code deletes a chunk from a game world if the chunk isn't currently active.
In my opinion, the version with the arrow function is a bit clearer,
but a better solution could be C++17's std::invoke. If I understand std::invoke
correctly, if C++ was to adopt std::invoke for algorithms, this code could
be written like this:
std::erase_if(active_chunks_, &Chunk::isInactive);
This looks nicer, but has the disadvantage that you need to add an extra method
to the class. Having both isActive and its negation isInactive as member functions
just because someone might want to use it as a predicate
in an algorithm sounds unfortunate. I prefer lambdas' fleixibilty.
Before:
return map(begin(worldgens_), end(worldgens_), [](auto &ptr) { return ptr.get(); });
After:
return map(begin(worldgens_), end(worldgens_), [](auto &ptr) => ptr.get());
This code maps a vector of unique pointers to raw pointers.
This is yet another case where I think the arrow syntax is slightly nicer than
the C++11 alternative, but this time, we could actually use the member function
invocation if I changed my map function to use std::invoke:
return map(begin(worldgens_), end(worldgens_), &std::unique_ptr<Swan::WorldGen::Factory>::get);
Well, this illustrates that invoking a member function doesn't really work with overly complex types. Imagine if the type was instead something more elaborate:
return map(begin(worldgens_), end(worldgens_),
std::unique_ptr<Swan::WorldGen<int>::Factory, Swan::WorldGen<int>::Factory::Deleter>::get);
This also happens to be unspecified behavior, because taking the address of a function in the standard library is generally not legal. From https://en.cppreference.com/w/cpp/language/extending_std:
The behavior of a C++ program is unspecified (possibly ill-formed) if it explicitly or implicitly attempts to form a pointer, reference (for free functions and static member functions) or pointer-to-member (for non-static member functions) to a standard library function or an instantiation of a standard library function template, unless it is designated an addressable function.
Before:
bool needRender = dirty || std::any_of(widgets.begin(), widgets.end(),
[](auto &w) { return w.needRender(); });
After:
bool needRender = dirty || std::any_of(widgets.begin(), widgets.end(),
[](auto &w) => w.needRender());
Again, the short lambda version looks a bit better to me. However, here again,
we could replace the lambda with a member reference if algorithms were
changed to use std::invoke:
bool needRender = dirty || std::any_of(widgets.begin(), widgets.end(),
&WidgetContainer::needRender);
Overall, I see a short lambda syntax as a modest improvement.
The biggest readability win mostly stems from the lack of that awkward
; }); at the end of an expression; foo([] => bar()) instead of
foo([] { return bar(); });. It certainly breaks down a bit when
the argument list is long; neither of these two lines are particularly short:
foo([](auto const &&a, auto const &&b, auto const &&c) => a + b + c);
foo([](auto const &&a, auto const &&b, auto const &&c) { return a + b + c; });
I think, considering the minimal cost of implementing this short lambda syntax, the modest improvements outweigh the added complexity. However, there's also an opportunity cost associated with my version of the short lambda syntax: it makes a better, future short lambda syntax either impossible or more challenging. For example, accepting my syntax would mean we couldn't really adopt a ratified version of P0573R2's short lambda syntax in the future, even if the issues with it were otherwise fixed.
Therefore, I will argue strongly that my syntax makes code easier to read, but I can't say anything about whether it should be standardized or not.
Aside: Corner cases
If we were to standardize this syntax, we would have to consider all kinds of corner cases, not just accept what clang with my changes happens to to do. However, I'm still curious about what exactly clang happens to do with my changes.
How does this interact with the comma operator?
The comma operator in C++ (and most C-based languages) is kind of strange.
For example, what does foo(a, b) do? We know it calls foo with the arguments
a and b, but you could technically decide to parse it as foo(a.operator,(b)).
My arrow syntax parses foo([] => 10, 20) as calling foo with one argument;
a function with the body 10, 20 (where the comma operator means the 10
does nothing, and 20 is returned). I would probably want that to be changed,
so that foo is called with two arguments; a lambda and an int.
This turns out to be fairly easy to fix, because Clang already has ways of
dealing with expressions which can't include top-level commas.
After all, there's precedence here; since clang parses foo(10, 20) without
interpreting the , a top-level comma as a comma operator, we can use the same
infrastructure for arrow lambdas.
In
clang/lib/Parser/ParseExpr.cpp,
Clang defines a function ParseAssignmentExpression, which has this comment:
Parse an expr that doesn't include (top-level) commas.
Calling ParseAssignmentExpression is also the first thing the ParseExpression
function does. It seems like it's just the general function for parsing an
expression without a top-level comma operator, even though the name is
somewhat misleading. This patch changes arrow lambdas to use
ParseAssignmentExpression instead of ParseExpression:
https://github.com/mortie/llvm/commit/c653318c0056d06a512dfce0799b66032edbed4c
How do immediately invoked lambdas work?
With C++11 lambdas, you can write an immediately invoked lambda in the obvious
way; just do [] { return 10; }(), and that expression will return 10.
With my arrow lambda syntax, it's not quite as obvious. Would [] => foo() be
interpreted as immediately invoking the lambda [] => foo, or would it be
interpreted as creating a lambda whose body is foo()?
In my opinion, the only sane way for arrow lambdas to work would be that
[] => foo() creates a lambda with the body foo(), and that creating
an immediately invoked lambda would require extra parens; ([] => foo())().
That's also how my implementation happens to work.
How does this interact with with explicit return types, specifiers, etc?
Since literally all the code before the arrow/opening brace is shared between arrow lambdas and C++11 lambdas, everything should work exactly the same. That means that all of these statements should work:
auto l1 = []() -> long => 10;
auto l2 = [foo]() mutable => foo++;
auto l3 = [](auto a, auto b) noexcept(noexcept(a + b)) => a + b;
And so would any other combination of captures, template params, params, specifiers, attributes, constraints, etc, except that the body has to be a single expression.