Yesterday, I read this blog post:
Wayland Cursor Lag: Just give me a break already...,
where a Linux user discusses their frustration with input latency under Wayland.
They detailed their own subjective experience of the problem,
but failed to produce hard evidence.
Even though I'm a very happy user of wayland overall,
I share the blog post's author's subjective impression that there's more
cursor lag under Wayland than under X11.
In my opinion, their experiment was limited by their phone camera's 90 FPS,
which really doesn't feel like it's enough to get conclusive numbers
when we're talking about differences which are probably on the order of
single screen refresh cycles.
So I thought: hey, I have a phone with a 240 FPS camera mode,
I bet that's enough to get some conclusive results!
Spoilers: I was right.
Experiment design
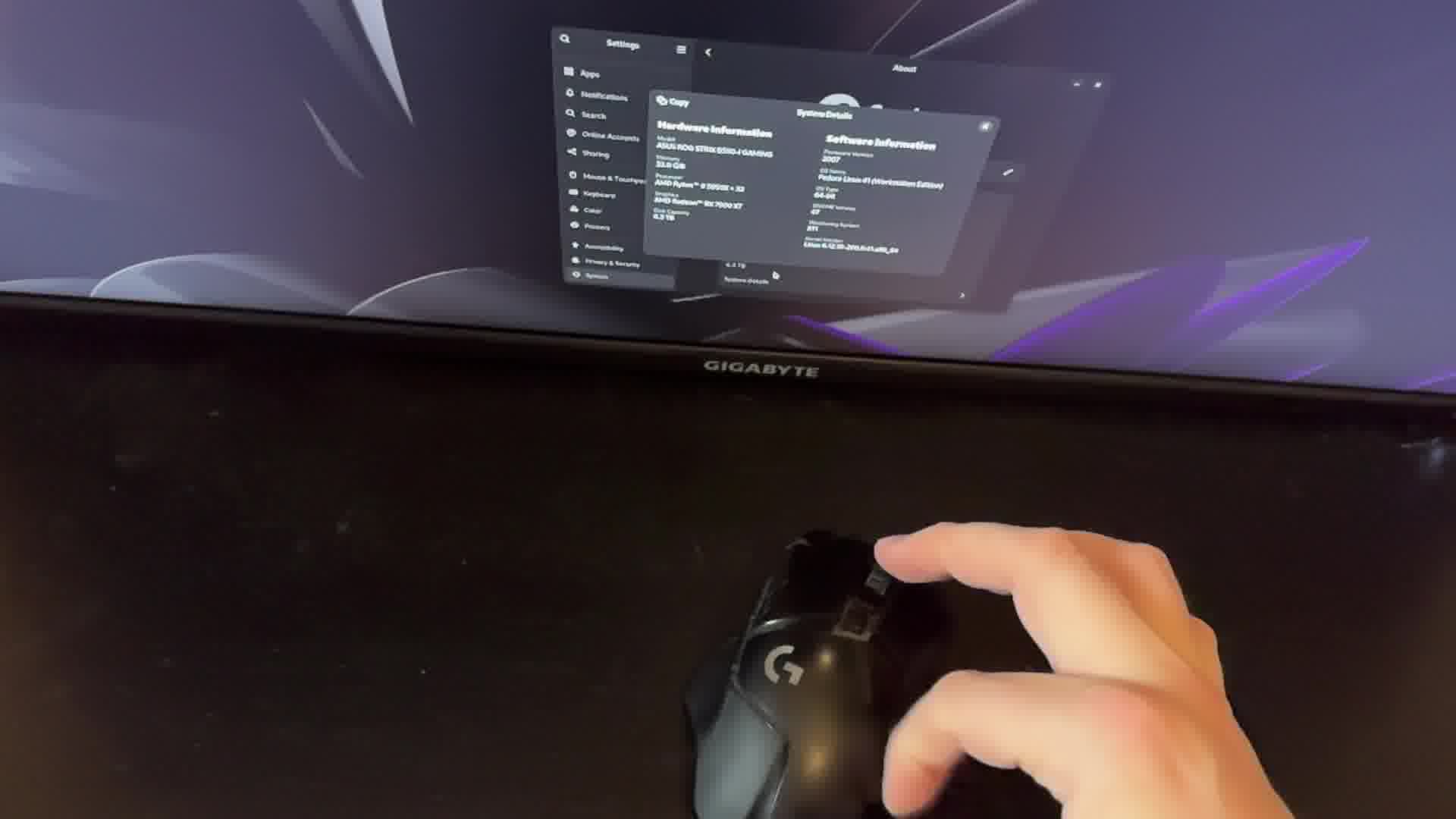
I simply pointed my phone's camera at the screen and desk using my left hand,
made sure to get the mouse cursor, the mouse and my right hand in frame,
and recorded myself repeatedly flicking the mouse with my finger.
I recorded myself flicking it 16 times under Wayland,
logged out of the GNOME Wayland session and into a GNOME X11 session,
then did the same there.
I then converted the two resulting video files into a series of JPEGs
using ffmpeg (ffmpeg -i <input file> %04d.jpg),
and counted from the first frame where I could see the mouse move
until the first frame where I could clearly see that the cursor had moved.
I elected to include the start and end frame;
so if I saw the mouse move in frame 1045,
then I saw the cursor move in frame 1047,
I would count that as 3 frames.
Here's an example which depicts a latency of 3 frames (requires JavaScript):
Here's a frame from before the mouse has begun moving.
The mouse still hasn't moved.
Here, the mouse has just about started moving,
so I consider this "frame 1".
The cursor hasn't moved yet.
The mouse moves a bit further, but the cursor still hasn't moved.
This is "frame 2".
This is the frame where the cursor starts moving.
This is "frame 3", so I would note down this sequence
as taking 3 frames.
Hardware details:
Distro: Fedora Workstation 41
GNOME version: 47
CPU: AMD Ryzen 9 5950X
GPU: AMD Radeon RX 7900XT
Monitor: Gigabyte M32U (4k IPS @ 144.99, no DPI scaling)
Mouse: Logitech G502 Lightspeed
Camera: iPhone 15 Pro, slo-mo 240 FPS
Limitations
The main limitations of this experiment are:
240 FPS still isn't that much. With my 144Hz screen, I have less than
two camera frames per screen refresh. This introduces some random variance.
Pixels don't switch instantly, so there are ambiguous frames where the cursor
is barely starting to become visible in its new location.
I decided to count the cursor as "having moved" when there is a clearly visible
cursor in a new location on the screen, even if the pixels haven't fully lit up.
For some reason, the video recording from my phone contains some duplicate frames.
I don't know why this happens. I decided to interpret these duplicate frames
as a representation of a frame's worth of time passing, so I counted them as normal.
All these factors introduce some uncertainty in the results.
However, they should affect Wayland and X11 equally, so with enough data,
it should all even out.
Update: Another caveat I should clearly point out is that there are
many other Wayland compositors out there than GNOME's, and I have not tested them.
For that matter, there are other GPU drivers out there than AMD's.
Other compositors and other GPU drivers may show different results.
Results
Here's the data I captured:
Variant
Video frames of latency
Average
Milliseconds
Refreshes
GNOME X11
5
4
3
4
5
4
6
5
1
4
4
4
3
4
4
4
4
16.7
2.4
GNOME Wayland
6
5
6
5
5
6
6
4
8
6
5
5
5
6
5
6
5.5625
23.2
3.3
Wayland, on average, has roughly 6.5ms more cursor latency than X11 on my system.
I don't have the statistics expertise necessary to properly analyze
whether this difference is statistically significant or not,
but to my untrained eye, it looks like there's a clear and consistent difference.
Interestingly, the difference is very close to 1 full screen refresh.
I don't know whether or not that's a coincidence.
Here are the numbers in chart form:
Conclusion
In my mind, these results are conclusive proof that there is a difference
in input latency between X11 and Wayland, at least with my hardware,
and that the difference is large enough that it's plausible for some people to notice.
Further testing on more varied hardware and refresh rates is necessary
to get a clear picture of how wide-spread the problem is and how large it is.
It's likely that the magnitude of the difference varies based on factors
such as which compositor is used and what the refresh rate of the screen is.
I probably won't undertake that further testing,
because this is all very time intensive work.
My goal was only to see if I could conclusively measure some difference.
Update: I want to add a note here about what this testing does not show.
It does not show that there's higher input latency in general
in Wayland compared to X11 in a way which affects, for example, games.
It is possible that this added latency is entirely cursor-specific
and that Wayland and X11 exhibit the exact same input latency
in graphical applications and games.
It is my understanding that the cursor is handled very differently from
normal graphical applications.
Further testing would be necessary to show whether Wayland has more input latency
in games than X11.
In this post, I hope to explore how interpreters are often implemented,
what a "virtual machine" means in this context, and how to make them faster.
Note: This post will contain a lot of C source code.
Most of it is fairly simple C which should be easy to follow,
but some familiarity with the C language is suggested.
What is a (virtual) machine?
For our purposes, a "machine" is anything which can read some sequence of instructions
("code") and act upon them.
A Turing machine
reads instructions from the cells of a tape and changes its state accordingly.
Your CPU is a machine which reads instructions in the form of binary data representing x86
or ARM machine code and modifies its state accordingly.
A LISP machine
reads instructions in the form of LISP code and modifies its state accordingly.
Your computer's CPU is a physical machine, with all the logic required to read and execute
its native machine code implemented as circuitry in hardware.
But we can also implement a "machine" to read and execute instructions in software.
A software implementation of a machine is what we call a virtual machine.
QEMU is an example of a project which implements common CPU instruction
sets in software, so we can take native machine code for ARM64 and run it in a
virtual ARM64 machine regardless of what architecture our physical CPU implements.
But we don't have to limit ourselves to virtual machines which emulate real CPU architectures.
In the world of programming languages, a "virtual machine" is usually used to mean something which
takes some language-specific code and executes it.
What is bytecode?
Many programming languages are separated into roughly two parts:
the front-end, which parses your textual source code and emits some form of machine-readable code,
and the virtual machine, which executes the instructions in this machine-readable code.
This machine-readable code that's inteneded to be executed by a virtual machine is usually called
"bytecode".
You're probably familiar with this from Java, where the Java compiler produces .class files
containing Java bytecode, and the Java Virtual Machine (JVM) executes these .class files.
(You may be more familiar with .jar files, which are essentially zip files with a bunch of
.class files.)
Python is also an example of a programming language with these two parts.
The only difference between Python's approach and Java's approach is that the Python compiler
and the Python virtual machine are part of the same executable, and you're not meant to distribute
the Python bytecode. But Python also generates bytecode files; the __pycache__ directories and
.pyc files Python generates contains Python bytecode. This lets Python avoid compiling your
source code to bytecode every time you run a Python script, speeding up startup times.
So how does this "bytecode" look like? Well, it usually has a concept of an "operation"
(represented by some numeric "op-code") and "operands" (some fixed numeric argument which somehow
modifies the behavior of the instruction).
But other than that, it varies wildly between languages.
Note: Sometimes "bytecode" is used interchangeably with any form of code intended to be
executed by a virtual machine.
Other times, it's used to mean specifically code where an instruction is always encoded
using exactly one byte for an "op-code".
Our own bytecode
In this post, we will invent our own bytecode with these characteristics:
Each operation is a 1-byte "op-code", sometimes followed by a 4-byte operand that's interpreted
as a 32-bit signed integer (little endian).
The machine has a stack, where each value on the stack is a 32-bit signed integer.
In the machine's model of the stack, stackptr[0] represents the value at the top of the stack,
stackptr[1] the one before that, etc.
This is the set of instructions our bytecode language will have:
00000000: CONSTANT c:
Push 'c' onto the stack.
> push(c);
00000001: ADD:
Pop two values from the stack, push their
sum onto the stack.
> b = pop();
> a = pop();
> push(a + b);
00000010: PRINT:
Pop a value from the stack and print it.
> print(pop());
00000011: INPUT:
Read a value from some external input,
and push it onto the stack.
> push(input())
00000100: DISCARD:
Pop a value from the stack and discard it.
> pop();
00000101: GET offset:
Find the value at the 'offset' from the
top of the stack and push it onto the stack.
> val = stackptr[offset];
> push(val);
0000110: SET offset:
Pop a value from the stack, replace the value
at the 'offset' with the popped value.
> val = pop();
> stackptr[offset] = val;
00000110: CMP:
Compare two values on the stack, push -1 if
the first is smaller than the second, 1 if the
first is bigger than the second, and 0 otherwise.
> b = pop();
> a = pop();
> if (a > b) push(1);
> else if (a < b) push(-1);
> else push(0);
00000111: JGT offset:
Pop the stack, jump relative to the given 'offset'
if the popped value is positive.
> val = pop();
> if (val > 0) instrptr += offset;
00001000: HALT:
Stop execution
I'm sure you can imagine expanding this instruction set with more instructions.
Maybe a SUB instruction, maybe more jump instructions, maybe more I/O.
If you want, you can play along with this post and expand my code
to implement your own custom instructions!
Throughout this blog post, I will be using an example program which multiplies two numbers together.
Here's the program in pseudocode:
A = input()
B = input()
Accumulator = 0
do {
Accumulator = Accumulator + A
B = B - 1
} while (B > 0)
print(Accumulator)
(This program assumes B is greater than 0 for simplicity.)
Here's that program implemented in our bytecode language:
INPUT // A = input()
INPUT // B = input()
CONSTANT 0 // Accumulator = 0
// Loop body:
// Accumulator + A
GET 0
GET 3
ADD
// Accumulator = <result>
SET 0
// B - 1
GET 1
CONSTANT -1
ADD
// B = <result>
SET 1
// B CMP 0
GET 1
CONSTANT 0
CMP
// Jump to start of loop body if <result> > 0
// We get the value -43 by counting the bytes from
// the first instruction in the loop body.
// Operations are 1 byte, operands are 4 bytes.
JGT -43
// Accumulator
GET 0
// print(<result>)
PRINT
HALT
Note: If you're viewing this in a browser with JavaScript enabled,
the above code should be interactive!
Press the Step or Run buttons to execute it.
The bar on the right represents the stack.
The yellow box indicates the current stack pointer,
a blinking green box means a value is being read,
a blinking red box means a value is being written.
The blue rectangle in the code area shows the instruction pointer.
You can also edit the code; try your hand at writing your own program!
You should take some moments to convince yourself that the bytecode truly reflects the pseudocode.
Maybe you can even imagine how you could write a compiler which takes a syntax tree reflecting
the source code and produces bytecode?
(Hint: Every expression and sub-expression leaves exactly one thing on the stack.)
Implementing a bytecode interpreter
A bytecode interpreter can be basically just a loop with a switch statement.
Here's my shot at implementing one in C for the bytecode language we invented:
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
enum op {
OP_CONSTANT, OP_ADD, OP_PRINT, OP_INPUT, OP_DISCARD,
OP_GET, OP_SET, OP_CMP, OP_JGT, OP_HALT,
};
void interpret(unsigned char *bytecode, int32_t *input) {
// Create a "stack" of 128 integers,
// and a "stack pointer" which always points to the first free stack slot.
// That means the value at the top of the stack is always 'stackptr[-1]'.
int32_t stack[128];
int32_t *stackptr = stack;
// Create an instruction pointer which keeps track of where in the bytecode we are.
unsigned char *instrptr = bytecode;
// Some utility macros, to pop a value from the stack, push a value to the stack,
// peek into the stack at an offset, and interpret the next 4 bytes as a 32-bit
// signed integer to read an instruction's operand.
#define POP() (*(--stackptr))
#define PUSH(val) (*(stackptr++) = (val))
#define STACK(offset) (*(stackptr - 1 - offset))
#define OPERAND() ( \
((int32_t)instrptr[1] << 0) | \
((int32_t)instrptr[2] << 8) | \
((int32_t)instrptr[3] << 16) | \
((int32_t)instrptr[4] << 24))
int32_t a, b;
// This is where we just run one instruction at a time, using a switch statement
// to figure out what to do in response to each op-code.
while (1) {
enum op op = (enum op)*instrptr;
switch (op) {
case OP_CONSTANT:
PUSH(OPERAND());
// We move past 5 bytes, 1 for the op-code, 4 for the 32-bit operand
instrptr += 5; break;
case OP_ADD:
b = POP();
a = POP();
PUSH(a + b);
// This instruction doesn't have an operand, so we move only 1 byte
instrptr += 1; break;
case OP_PRINT:
a = POP();
printf("%i\n", (int)a);
instrptr += 1; break;
case OP_INPUT:
PUSH(*(input++));
instrptr += 1; break;
case OP_DISCARD:
POP();
instrptr += 1; break;
case OP_GET:
a = STACK(OPERAND());
PUSH(a);
instrptr += 5; break;
case OP_SET:
a = POP();
STACK(OPERAND()) = a;
instrptr += 5; break;
case OP_CMP:
b = POP();
a = POP();
if (a > b) PUSH(1);
else if (a < b) PUSH(-1);
else PUSH(0);
instrptr += 1; break;
case OP_JGT:
a = POP();
if (a > 0) instrptr += OPERAND();
else instrptr += 5;
break;
case OP_HALT:
return;
}
}
}
That's it. That's a complete virtual machine for our little bytecode language.
Let's give it a spin! Here's a main function which exercises it:
Note: We use two's complement
to represent negative numbers, because that's what the CPU does.
A 32-bit number can represent the numbers between 0 and 4'294'967'295.
Two's complement is a convention where the numbers between 0 and 2'147'483'647
are treated normally, and the numbers between 2'147'483'648 and 4'294'967'295
represent the numbers between -2'147'483'648 and -1.
Little-endian just means that order of the bytes are "swapped" compared to what you'd expect.
For example, to express the number 35799 (10001011'11010111 in binary) as 2 bytes in
little-endian, we put the last 8 bits first and the first 8 bits last:
unsigned char bytes[] = {0b11010111, 0b10001011}.
It's a bit counter-intuitive, but it's how most CPU architectures these days represent numbers
larger than one byte.
When I compile and run the full C program with the inputs 3 and 5, it prints 15. Success!
If I instead ask it to calculate 1 * 100'000'000,
my laptop (Apple M1 Pro, Apple Clang 14.0.0 with -O3) runs the program in 1.4 seconds.
My desktop (AMD R9 5950x, GCC 12.2.0 with -O3) runs the same program in 1.1 seconds.
The loop contains 12 instructions, and there are 6 instructions outside of the loop,
so a complete run executes 100'000'000*12+6=1'200'000'006 instructions.
That means my laptop runs 856 million bytecode instructions per second ("IPS") on average,
and my desktop runs 1.1 billion instructions per second.
Note: The actual benchmarked code defines the program variable in a separate
translation unit from the main function and interpret function,
and link-time optimization is disabled.
This prevents the compiler from optimizing based on the knowledge of the bytecode program.
Not bad, but can we do better?
Managing our own jump table
Looking at Godbolt, the assembly generated for our
loop + switch is roughly like this:
Note: This isn't real x86 or ARM assembly, but it gives an idea of what's going on
without getting into the weeds of assembly syntax.
We can see that the compiler generated a jump table; a table of memory addresses to jump to.
At the beginning of each iteration of the loop, it looks up the target address in the jump table
based on the opcode at the instruction pointer, then jumps to it.
And at the end of executing each switch case, it jumps back to the beginning of the loop.
This is fine, but it's a bit unnecessary to jump to the start of the loop just to immediately
jump again based on the next op-code. We could just replace the jmp loop with
jmp jmp_table[*instrptr] like this:
This has the advantage of using one less instruction per iteration, but that's negligible;
completely predictable jumps such as our jmp loop are essentially free.
However, there's a much bigger advantage: the CPU can exploit the inherent predictability of
our bytecode instruction stream to improve its branch prediction.
For example, a CMP instruction is usually going to be followed
by the JGE instruction, so the CPU can start
speculatively executing the JGE instruction
before it's even done executing the CMP instruction.
(At least that's what I believe is happeneing; figuring out why something is as fast or slow
as it is, at an instruction-by-instruction level, is incredibly difficult on modern CPUs.)
Sadly, standard C doesn't let us express this style of jump table.
But GNU C does! With
GNU's Labels as Values extension,
we can create our own jump table and indirect goto:
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
enum op {
OP_CONSTANT, OP_ADD, OP_PRINT, OP_INPUT, OP_DISCARD,
OP_GET, OP_SET, OP_CMP, OP_JGT, OP_HALT,
};
void interpret(unsigned char *bytecode, int32_t *input) {
int32_t stack[128];
int32_t *stackptr = stack;
unsigned char *instrptr = bytecode;
#define POP() (*(--stackptr))
#define PUSH(val) (*(stackptr++) = (val))
#define STACK(offset) (*(stackptr - 1 - offset))
#define OPERAND() ( \
((int32_t)instrptr[1] << 0) | \
((int32_t)instrptr[2] << 8) | \
((int32_t)instrptr[3] << 16) | \
((int32_t)instrptr[4] << 24))
// Note: This jump table must be synchronized with the 'enum op',
// so that `jmptable[op]` represents the label with the code for the instruction 'op'
void *jmptable[] = {
&&case_constant, &&case_add, &&case_print, &&case_input, &&case_discard,
&&case_get, &&case_set, &&case_cmp, &&case_jgt, &&case_halt,
};
int32_t a, b;
goto *jmptable[*instrptr];
case_constant:
PUSH(OPERAND());
instrptr += 5; goto *jmptable[*instrptr];
case_add:
b = POP();
a = POP();
PUSH(a + b);
instrptr += 1; goto *jmptable[*instrptr];
case_print:
a = POP();
printf("%i\n", (int)a);
instrptr += 1; goto *jmptable[*instrptr];
case_input:
PUSH(*(input++));
instrptr += 1; goto *jmptable[*instrptr];
case_discard:
POP();
instrptr += 1; goto *jmptable[*instrptr];
case_get:
a = STACK(OPERAND());
PUSH(a);
instrptr += 5; goto *jmptable[*instrptr];
case_set:
a = POP();
STACK(OPERAND()) = a;
instrptr += 5; goto *jmptable[*instrptr];
case_cmp:
b = POP();
a = POP();
if (a > b) PUSH(1);
else if (a < b) PUSH(-1);
else PUSH(0);
instrptr += 1; goto *jmptable[*instrptr];
case_jgt:
a = POP();
if (a > 0) instrptr += OPERAND();
else instrptr += 5;
goto *jmptable[*instrptr];
case_halt:
return;
}
With this interpreter loop, my laptop calculates 1 * 100'000'000 in 898ms,
while my desktop does it in 1 second.
It's interesting that Clang + M1 is significantly slower than GCC + AMD with the basic interpreter
but significantly faster for this custom jump table approach.
At least it's a speed-up in both cases.
Getting rid of the switch entirely with tail calls
Both of the implementations so far have essentially been of the form, "Look at the current instruction,
and decide what code to run with some kind of jump table". But we don't actually need that.
Instead of doing the jump table look-up every time, we could do the look-up once for every instruction
before starting execution.
Instead of an array of op codes, we could have an array of pointers to some machine code.
The easiest and most standard way to do this would be to have each instruction as its own function,
and let that function tail-call the next function. Here's an implementation of that:
This time, we can't just feed our interpreter an array of bytes as the bytecode,
since there isn't really "an interpreter", there's just a collection of functions.
We can manually create a program containing function pointers like this:
In a real use-case, you would probably want to have some code to automatically generate
such an array of union instr based on bytecode, but we'll ignore that for now.
With this approach, my laptop calculates 1 * 100'000'000 in 841ms,
while my desktop does it in only 553ms.
It's not a huge improvement for the Clang + M1 case, but it's almost twice as fast with GCC + AMD!
And compared to the previous approach, it's written in completely standard ISO C99,
with the caveat that the compiler must perform tail call elimination.
(Most compilers will do this at higher optimization levels, and most compilers
let us specify per-function optimization levels with pragmas, so that's not a big issue in practice.)
Note: The timings from the benchmark includes the time it takes to convert the bytecode
into this function pointer array form.
Final step: A compiler
All approaches so far have relied on finding ever faster ways to select which source code snippet
to run next.
As it turns out, the fastest way to do that is to simply put the right source code snippets
after each other!
If we have the following bytecode:
CONSTANT 5
INPUT
ADD
PRINT
We can just generate C source code to do what we want:
PUSH(5);
PUSH(INPUT());
b = POP();
a = POP();
PUSH(a + b);
printf("%i\n", (int)POP());
We can then either shell out to GCC/Clang, or link with libclang to compile the generated C code.
This also lets us take advantage of those projects's excellent optimizers.
Note: At this point, we don't have a "virtual machine" anymore.
One challenge is how to deal with jumps.
The easiest solution from a code generation perspective is probably to wrap all the code
in a switch statement in a loop:
int32_t index = 0;
while (1) {
switch (index) {
case 0:
PUSH(5);
case 5:
PUSH(INPUT());
case 6:
a = POP();
b = POP();
PUSH(a + b);
case 7:
printf("%i\n", (int)POP());
}
}
With this approach, a jump to instruction N becomes index = N; break;.
Note: Remember that in C, switch statement cases fall through to the next case
unless you explicitly jump to the end with a break.
So once the code for instruction 5 is done, we just fall through to instruction 6.
Here's my implementation:
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
enum op {
OP_CONSTANT, OP_ADD, OP_PRINT, OP_INPUT, OP_DISCARD,
OP_GET, OP_SET, OP_CMP, OP_JGT, OP_HALT,
};
void write_operand(unsigned char *i32le, FILE *out) {
fprintf(out, " operand = %i;\n",
(int)i32le[0] | (int)i32le[1] << 8 | (int)i32le[2] << 16 | (int)i32le[3] << 24);
}
void compile(unsigned char *bytecode, size_t size, FILE *out) {
fputs(
"#include <stdio.h>\n"
"#include <stdint.h>\n"
"#include <stdlib.h>\n"
"\n"
"int main(int argc, char **argv) {\n"
" int32_t stack[128];\n"
" int32_t *stackptr = stack;\n"
" char **inputptr = &argv[1];\n"
"\n"
"#define POP() (*(--stackptr))\n"
"#define PUSH(val) (*(stackptr++) = (val))\n"
"#define STACK(offset) (*(stackptr - 1 - offset))\n"
"\n"
" int32_t a, b, operand;\n"
" int32_t index = 0;\n"
" while (1) switch (index) {\n",
out);
for (size_t i = 0; i < size;) {
fprintf(out, " case %zi:\n", i);
enum op op = (enum op)bytecode[i];
switch (op) {
case OP_CONSTANT:
write_operand(&bytecode[i + 1], out);
fputs(" PUSH(operand);\n", out);
i += 5; break;
case OP_ADD:
fputs(
" b = POP();\n"
" a = POP();\n"
" PUSH(a + b);\n",
out);
i += 1; break;
case OP_PRINT:
fputs(
" a = POP();\n"
" printf(\"%i\\n\", (int)a);\n",
out);
i += 1; break;
case OP_INPUT:
fputs(" PUSH(atoi(*(inputptr++)));\n", out);
i += 1; break;
case OP_DISCARD:
fputs(" POP();\n", out);
i += 1; break;
case OP_GET:
write_operand(&bytecode[i + 1], out);
fputs(
" a = STACK(operand);\n"
" PUSH(a);\n",
out);
i += 5; break;
case OP_SET:
write_operand(&bytecode[i + 1], out);
fputs(
" a = POP();\n"
" STACK(operand) = a;\n",
out);
i += 5; break;
case OP_CMP:
fputs(
" b = POP();\n"
" a = POP();\n"
" if (a > b) PUSH(1);\n"
" else if (a < b) PUSH(-1);\n"
" else PUSH(0);\n",
out);
i += 1; break;
case OP_JGT:
write_operand(&bytecode[i + 1], out);
fprintf(out,
" a = POP();\n"
" if (a > 0) { index = %zi + operand; break; }\n",
i);
i += 5; break;
case OP_HALT:
fputs(" return 0;\n", out);
i += 1; break;
}
}
fputs(
" }\n"
"\n"
" abort(); // If we get here, there's a missing HALT\n"
"}",
out);
}
If we run our compiler on the bytecode for our multiplication program, it outputs this C code:
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int32_t stack[128];
int32_t *stackptr = stack;
char **inputptr = &argv[1];
#define POP() (*(--stackptr))
#define PUSH(val) (*(stackptr++) = (val))
#define STACK(offset) (*(stackptr - 1 - offset))
int32_t a, b, operand;
int32_t index = 0;
while (1) switch (index) {
case 0:
PUSH(atoi(*(inputptr++)));
case 1:
PUSH(atoi(*(inputptr++)));
case 2:
operand = 0;
PUSH(operand);
case 7:
operand = 0;
a = STACK(operand);
PUSH(a);
/* ... */
case 49:
b = POP();
a = POP();
if (a > b) PUSH(1);
else if (a < b) PUSH(-1);
else PUSH(0);
case 50:
operand = -43;
a = POP();
if (a > 0) { index = 50 + operand; break; }
case 55:
operand = 0;
a = STACK(operand);
PUSH(a);
case 60:
a = POP();
printf("%i\n", (int)a);
case 61:
return 0;
}
abort(); // If we get here, there's a missing HALT
}
If we compile the generated C code with -O3, my laptop runs the 1 * 100'000'000 calculation in 204ms!
That's over 4 times faster than the fastest interpreter we've had so far.
That also means we're executing our 1'200'000'006 bytecode instructions at 5'882 million
instructions per second! Its CPU only runs at 3'220 million CPU clock cycles per second, meaning
it's spending significantly less than a clock cycle per bytecode instruction on average.
My desktop with GCC is doing even better, executing all the code in 47ms, which means a whopping
25.7 billion instructions per second!
Note that in this particular case, the compiler is able to see that some instructions always
happen after each other, which means it can optimize across bytecode instructions.
For example, the bytecode contains a sequence GET 1; CONSTANT -1; ADD;, which the compiler
is able to prove you won't ever jump into the middle of, so it optimizes out all the implied
stack manipulation code; it's optimized into a single sub instruction which subtracts the
constant 1 from one register and writes the result to another.
This is kind of an important point. The compiler can generate amazing code, if it can figure out
which instructions (i.e switch cases) are potential jump targets.
This is information you probably have access to in the source code,
so it's worth thinking about how you can design your bytecode such that GCC or Clang can figure it out
when looking at your compiler output.
One approach could be to add "label" bytecode instructions, and only permit jumping to such a label.
With our bytecode, the only jump instruction we have jumps to a known location, since the jump
offset is an immediate operand to the instruction.
If we added an instruction which reads the jump target from the stack instead,
we might quickly get into situations where GCC/Clang has lost track of which instructions
can be jump targets, and must therefore make sure not to optimize across instruction boundaries.
We can preventing the compiler from optimizing across instruction boundaries
by inserting this code after the case 61: (the code for the HALT instruction):
if (argc > 100) { PUSH(argc); index = argc % 61; break; }
With this modification, every single instruction might be a branch target,
so every instruction must make sense in its own right regardless of which instruction
was executed before or how the stack looks.
This time, the 1 * 100'000'000 calculation happens in 550ms on my laptop with Clang,
which is still not bad. It means we're executing 2'181 million bytecode instructions per second.
My desktop is doing even better, at 168ms.
At this point, I got curious about whether it's the CPU or the compiler making the difference,
so the next table contains all the benchmarks for both compilers on both systems.
I have no intelligent commentary on those numbers. They're all over the place.
In the basic interpreter case for example, GCC is much faster than Clang on the AMD CPU,
but Clang is much faster than GCC on the Apple CPU.
It's the opposite in the custom jump table case, where GCC is much master than Clang on the Apple CPU,
but Clang is much faster than GCC on the AMD CPU.
The overall pattern we've been looking at holds though, for the most part:
for any given CPU + compiler combination, every implementation I've introduced is faster than
the one before it.
The big exception is the tail call version, where the binary compiled by GCC performs horribly on
the Apple CPU (even though it performs excellently on the AMD CPU!).
If anything though, this mess of numbers indicates the value of knowing about all the different
possible approaches and choosing the right one for the situation.
Which takes us to...
Bringing it all together
We have 4 different implementations of the same bytecode , all with different advantages
and drawbacks.
And even though every instruction does the same thing in every implementation,
we have written 4 separate implementations of every instruction.
That seems unnecessary. After all, we know that ADD, in every implementation,
will do some variant of this:
b = POP();
a = POP();
PUSH(a + b);
GO_TO_NEXT_INSTRUCTION();
What exactly it means to POP or to PUSH or to go to the next instruction
might depend on the implementation,
but the core functionality is the same for all of them.
We can utilize that regularity to specify the instructions only once
in a way that's re-usable across implementations using so-called
X macros.
We create a file instructions.x which contains code to define all our instructions:
Let's say we want to create an instructions.h which contains an enum op with all the operation
types and a const char *op_names[] which maps enum values to strings.
We can implement that by doing something like this:
This code might look a bit confusing at first glance, but it makes sense:
we have generic descriptions of instructions in the instructions.x file,
and then we define a macro called X to extract information from those descriptions.
It's basically a weird preprocessor-based application of the
visitor pattern.
In the above example, we use the instruction definitions twice: once to define the enum op,
and once to define the const char *op_names[].
If we run the code through the preprocessor, we get something rouhly like this:
Now let's say we want to write a function which executes an instruction.
We could write that function like this:
void execute(enum op op) {
switch (op) {
#define X(name, has_operand, code...) case OP_ ## name: code break;
#include "instructions.x"
#undef X
}
}
Which expands to:
void execute(enum op op) {
switch (op)
case OP_CONSTANT:
{
PUSH(OPERAND());
NEXT();
} break;
case OP_ADD:
{
b = POP();
a = POP();
PUSH(a + b);
NEXT();
} break;
}
}
Note: We use a variadic argument for the code block because the C preprocessor has
annoying splitting rules. Code such as X(FOO, 1, {int32_t a, b;}) would call the macro
X with 4 arguments: FOO, 1, {int32_t a, and b;}.
Using a variadic argument "fixes" this, because when we expand code in the macro body,
the preprocessor will insert a comma between the arguments.
You can read about more stupid preprocessor hacks here:
https://mort.coffee/home/obscure-c-features/
This is starting to look reasonable, but it doesn't quite work.
We haven't defined those PUSH/OPERAND/NEXT/POP macros, nor the a and b variables.
We need to be a bit more rigorous about what exactly is expected by the instruction,
and what's expected by the environment which the instruction's code is expanded into.
So let's design a sort of "contract" between the instruction and the execution environment.
The environment must:
Provide a POP() macro which pops the stack and evaluates to the result.
Provide a PUSH(val) macro which push the value to the stack.
Provide a STACK(offset) macro which evaluates to an
lvalue
for the stack value at offset.
Provide an OPERAND() macro which evaluates to the current instruction's operand as a int32_t.
Provide an INPUT() macro which reads external input and evaluates to the result.
Provide a PRINT(val) macro which outputs the value somehow (such as by printing to stdout).
Provide a GOTO_RELATIVE(offset) macro which jumps to currentInstruction + offset
Provide a NEXT() macro which goes to the next instruction
Provide a HALT() macro which halts execution.
Provide the variables int32_t a and int32_t b as general-purpose variables.
(This turns out to significantly speed up execution in some cases compared to
defining the variables locally within the scope.)
As for the instruction:
It must call X(name, has_operand, code...) with an identifier for name, a 0 or 1 for
has_operand, and a brace-enclosed code block for code....
The code block may only invoke OPERAND() if it has set has_operand to 1.
The code block must only contain standard C code and calls to the macros we defined earlier.
The code block must not try to directly access any other variables which may exist
in the context in which it is expanded.
The code block can assume that the following C headers are included: <stdio.h>, <stdlib.h>,
<stdint.h>.
The code must not change the stack pointer and dereference it in the same expression
(essentially, no PUSH(STACK(1)), since there's no
sequence point between the dereference and
the increment).
With this, we can re-implement our basic bytecode interpreter:
And that's it! That's our whole generic basic bytecode interpreter, defined using the
instruction definitions in instructions.x.
And any time we add more bytecode instructions to instructions.x,
the instructions are automatically added to the enum op and const char *op_names[] in
instructions.h, and they're automatically supported by this new basic interpreter.
I won't deny that this style of code is a bit harder to follow than straight C code.
However, I've seen VM with their own custom domain-specific languages and code generators
to define instructions, and I find that much harder to follow than this preprocessor-based approach.
Even though the C preprocessor is flawed in many ways, it has the huge advantage that C programmers
already understand how it works for the most part, and they're used to following code which
uses macros and includes.
With decent comments in strategic places, I don't think this sort of "abuse" of the C preprocessor
is wholly unreasonable.
Your mileage may differ though, and my threshold for "too much preprocessor magic"
might be set too high.
For completeness, let's amend instructions.x with all the instructions in the bytecode language
I defined at the start of this post:
X(CONSTANT, 1, {
PUSH(OPERAND());
NEXT();
})
X(ADD, 0, {
b = POP();
a = POP();
PUSH(a + b);
NEXT();
})
X(PRINT, 0, {
PRINT(POP());
NEXT();
})
X(INPUT, 0, {
PUSH(INPUT());
NEXT();
})
X(DISCARD, 0, {
(void)POP();
NEXT();
})
X(GET, 1, {
a = STACK(OPERAND());
PUSH(a);
NEXT();
})
X(SET, 1, {
a = POP();
STACK(OPERAND()) = a;
NEXT();
})
X(CMP, 0, {
b = POP();
a = POP();
if (a > b) PUSH(1);
else if (a < b) PUSH(-1);
else PUSH(0);
NEXT();
})
X(JGT, 1, {
a = POP();
if (a > 0) { GOTO_RELATIVE(OPERAND()); }
else { NEXT(); }
})
X(HALT, 0, {
HALT();
})
Implementing the custom jump table variant and the tail-call variant using this X-macro system
is left as an exercise to the reader.
However, just to show that it's possible, here's the compiler variant implemented generically:
I thought I should mention that the techniques described in this post won't magically make any
interpreted language much faster.
The main source of the performance differences we have explored here is due to the overhead
involved in selecting which instruction to execute next; the code which runs between
the instructions.
By reducing this overhead, we're able to make our simple bytecode execute blazing fast.
But that's really only because all our instructions are extremely simple.
In the case of something like Python, each instruction might be much more complex to execute.
The BINARY_ADD operation, for example, pops two values from the stack, adds them together,
and pushes the result onto the stack, much like how our bytecode's ADD operation does.
However, our ADD operation knows that the two popped values are 32-bit signed integers.
In Python, the popped values may be strings, they may be arrays, they may be numbers, they may be
objects with a custom __add__ method, etc.
This means that the time it takes to actually execute instructions in Python will dominate
to the point that speeding up instruction dispatch is likely insignificant.
Optimizing highly dynamic languages like Python kind of requires some form of
tracing JIT
to stamp out specialized functions which make assumptions about what types their arguments are,
which is outside the scope of this post.
But that doesn't mean the speed-up I have shown here is unrealistic.
If you're making a language with static types, you can have dedicated fast instructions
for adding i32s, adding doubles, etc.
And at that point, the optimizations shown in this post will give drastic speed-ups.
Further reading
I watched this video about a year ago ago:
Cheaply writing a fast interpreter - Neil Mitchell.
I can't directly cite anything specific,
but some ideas such as converting the instruction stream to an array of function pointers
comes from that talk.
So those are my thoughts on speeding up virtual machine execution.
If you want, you may check out my programming languages
Gilia and osyris.
Neither makes use of any of the techniques discussed in this post,
but playing with Gilia's VM is what got me started down this path of exploring different techniques.
If I ever get around to implementing these ideas into Gilia's VM,
I'll add a link to the relevant parts of the source code here.
(If you're here from Google and just need help with tar being slow:
If you trust the tar archive, extract with -P to make tar fast.)
A couple of days ago, I had a 518GiB tar.gz file (1.1 TiB uncompressed) that I had to extract.
At first, GNU tar was doing a great job, chewing through the tar.gz at around 100MiB/s.
But after a while, it slowed significantly; down to less than a kilobyte per second.
pv's time estimate went from a bit over an hour,
to multiple hours, to over a day, to almost a week.
After giving it some time, and after failing to find anything helpful through Google,
I decided that learning the tar file format and making my own tar extractor would probably be faster
than waiting for tar.
And I was right; before the day was over, I had a working tar extractor,
and I had successfully extracted my 1.1TiB tarball.
I will explain why GNU tar is so slow later in this post, but first, let's take a look at:
The original tar file format
Tar is pretty unusual for an archive file format.
There's no archive header, no index of files to fascilitate seeking, no magic bytes to help file
and its ilk detect whether a file is a tar archive, no footer, no archive-wide metadata.
The only kind of thing in a tar file is a file object.
So, how do these file objects look?
Well, they start with a 512-byte file object header which looks like this:
Followed by ceil(file_size / 512) 512-byte blocks of payload (i.e file contents).
We have most of the attributes we would expect a file object to have:
the file path, the mode, the modification time (mtime), the user/group ID, the file size,
and the file type.
To support symlinks and hard links, there's also a link path.
The original tar file format defines these possible values for the file_type field:
'0' (or sometimes '\0', the NUL character): Normal file
'1': Hard link
'2': Symbolic link
Future extensions to tar implements additional file types, among them '5', which represents a directory.
Some old tar implementations apparently used a trailing slash '/' in a '0'-type file object
to represent directories, at least according to Wikipedia.
You may think that the numeric values (file_mode, file_size, file_mtime, ...) would be
encoded in base 10, or maybe in hex, or using plain binary numbers ("base 256").
But no, they're actually encoded as octal strings (with a NUL terminator,
or sometimes a space terminator).
Tar is the only file format I know of which uses base 8 to encode numbers.
I don't quite understand why, since octal is neither space-efficient nor human-friendly.
When representing numbers in this post, I will write them in decimal (base 10).
To encode a tar archive with one file called "hello.txt" and the content "Hello World",
we need two 512-byte blocks:
Bytes 512-1023: "Hello World", followed by 501 zero bytes
In addition, a tar file is supposed to end with 1024 zero-bytes to represent an end-of-file marker.
The two big limitations of the original tar format is that paths can't be longer than 100 characters,
and files can't be larger than 8GiB (8^11 bytes).
Otherwise though, I quite like the simplicity of the format.
We'll discuss how various extensions address the limitations later,
but first, let's try to implement an extractor:
(Feel free to skip this source code, but you should at least skim the comments)
// tarex.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#include <string.h>
struct file_header {
char file_path[100];
char file_mode[8];
char owner_user_id[8];
char owner_group_id[8];
char file_size[12];
char file_mtime[12];
char header_checksum[8];
char file_type;
char link_path[100];
char padding[255];
};
// We don't bother with great error reporting, just abort on error
#define check(x) if (!(x)) abort()
// Utilities to abort on short read/write
#define xfread(ptr, size, f) check(fread(ptr, 1, size, f) == size)
#define xfwrite(ptr, size, f) check(fwrite(ptr, 1, size, f) == size)
// Tar represents all its numbers as octal
size_t parse_octal(char *str, size_t maxlen) {
size_t num = 0;
for (size_t i = 0; i < maxlen && str[i] >= '0' && str[i] <= '7'; ++i) {
num *= 8;
num += str[i] - '0';
}
return num;
}
// Extract one file from the archive.
// Returns 1 if it extracted something, or 0 if it reached the end.
int extract(FILE *f) {
unsigned char header_block[512];
xfread(header_block, sizeof(header_block), f);
struct file_header *header = (struct file_header *)header_block;
// The end of the archive is represented with blocks of all-zero content.
// For simplicity, assume that if the file path is empty, the block is all zero
// and we reached the end.
if (header->file_path[0] == '\0') {
return 0;
}
// The file path and link path fields aren't always 0-terminated, so we need to copy them
// into our own buffers, otherwise we break on files with exactly 100 character paths.
char file_path[101] = {0};
memcpy(file_path, header->file_path, 100);
char link_path[101] = {0};
memcpy(link_path, header->link_path, 100);
// We need these for later
size_t file_size = parse_octal(header->file_size, sizeof(header->file_size));
FILE *out_file = NULL;
if (header->file_type == '0' || header->file_type == '\0') {
// A type of '0' means that this is a plain file.
// Some early implementations also use a NUL character ('\0') instead of an ASCII zero.
fprintf(stderr, "Regular file: %s\n", file_path);
out_file = fopen(file_path, "w");
check(out_file != NULL);
} else if (header->file_type == '1') {
// A type of '1' means that this is a hard link.
// That means we create a hard link at 'file_path' which links to the file at 'link_path'.
fprintf(stderr, "Hard link: %s -> %s\n", file_path, link_path);
check(link(link_path, file_path) >= 0);
} else if (header->file_type == '2') {
// A type of '2' means that this is a symbolic link.
// That means we create a symlink at 'file_path' which links to the file at 'link_path'.
fprintf(stderr, "Symbolic link: %s -> %s\n", file_path, link_path);
check(symlink(link_path, file_path) >= 0);
} else if (header->file_type == '5') {
// A type of '5' means that this is a directory.
fprintf(stderr, "Directory: %s\n", file_path);
check(mkdir(file_path, 0777) >= 0);
// Directories sometimes use the size field, but they don't contain data blocks.
// Zero out file_size to avoid skipping entries.
file_size = 0;
} else {
// There are other possible fields added by various tar implementations and standards,
// but we'll ignore those for this implementation.
fprintf(stderr, "Unsupported file type %c: %s\n", header->file_type, file_path);
}
// We have read the header block, now we need to read the payload.
// If we're reading a file (i.e if 'outfile' is non-NULL) we will also write the body,
// but otherwise we'll just skip it.
char block[512];
while (file_size > 0) {
xfread(block, sizeof(block), f);
size_t n = file_size > 512 ? 512 : file_size;
file_size -= n;
if (out_file != NULL) {
xfwrite(block, n, out_file);
}
}
if (out_file != NULL) {
check(fclose(out_file) >= 0);
}
// Indicate that we have successfully extracted a file object, and are ready to read the next
return 1;
}
int main() {
while (extract(stdin));
}
The first major extension to the tar file format we will look at is the UStar format,
which increases the file length limit to 256 characters and adds some new file types.
The header is expanded to this:
We now have some magic bytes (defined to be "ustar\0" for the UStar format),
as well as the owner user/group names.
But most importantly, we have a prefix field, which allows up to 256 character file paths.
With UStar, instead of just extracting the bytes from file_path and link_path like before,
we must construct a file path like this:
void read_path(char dest[257], char path[100], char prefix[100]) {
// If there's no prefix, use name directly
if (prefix[0] == '\0') {
memcpy(dest, path, 100);
dest[100] = '\0';
return;
}
// If there is a prefix, the path is: <prefix> '/' <path>
size_t prefix_len = strnlen(prefix, 155);
memcpy(dest, prefix, prefix_len);
dest[prefix_len] = '/';
memcpy(&dest[prefix_len + 1], path, 100);
dest[256] = '\0';
}
int extract(FILE *f) {
/* ... */
char file_path[257];
read_path(file_path, header->file_path, header->prefix);
char link_path[257];
read_path(link_path, header->link_path, header->prefix);
/* ... */
}
The original tar format had the file types '0' (or '\0'), '1' and '2',
for regular files, hard links and symlinks.
UStar defines these additional file types:
'3' and '4': Character devices and block devices. These are the reason for the new
device_major_number and device_minor_number fields.
'5': Directories.
'6': FIFO files.
'7': Contiguous files. This type isn't really used much these days, and most implementations
just treat it as a regular file.
This is definitely an improvement, but we can still only encode up to 256 character long paths.
And that 8GiB file size limit still exists. Which leads us to:
The pax file format
The POSIX.1-2001 standard introduced the pax command line tool, and with it, a new set of
extensions to the tar file format.
This format is identical to UStar, except that it adds two new file object types: 'x' and 'g'.
Both of these types let us define "extended header records", as the spec calls it.
Records set with 'x' apply to only the next file, while records set with 'g' apply to all
following files.
With this new extended header, we can encode the access and modification times with more precision,
user/group IDs above 8^7, file sizes over 8^11, file paths of arbitrary length, and a whole lot more.
The records are in the payload of the extended headr file object,
and use a simple length-prefixed key/value syntax.
To represent our "hello.txt" example file with an access time attribute,
we need these four 512-byte blocks:
Header, type='x', file_size=30
"30 atime=1658409251.551879906\n", followed by 482 zeroes
Interestingly, these extended header records all seem to use decimal (base 10).
On the one hand, using base 10 makes sense, but on the other hand, wouldn't it be nice to stick to
one way of representing numbers?
Anyways, we can see that the file format has become quite complex now.
Just the file path can be provided in any of four different ways:
The full path might be in the file_path field.
The path might be a combination of the prefix and the file_path fields.
The previous file object might've been an 'x' type record with set a path property.
There might've been some 'g' type file object earlier in the archive which set a path property.
The GNU tar file format
GNU tar has its own file format, called gnu, which is different from the pax format.
Like pax, the gnu format is based on UStar, but it has a different way of encoding
arbitrary length paths and large file sizes:
It introduces the 'L' type, where the payload of the file object represents the file_path
of the next file object.
It introduces the 'K' type, where the payload of the file object represents the link_path
of the next file object.
A link with both a long file_path and a long link_path is preceeded by both an 'L' type
file object and a 'K' type file object. The order isn't specified from what I can tell.
If a file is over 8GiB, it will set the high bit of the first character in file_size,
and the rest of the string is parsed as base 256 (i.e it's treated as a 95-bit integer, big endian).
In some ways, I prefer this approach over the pax approach, since it's much simpler;
the pax format requires the extractor to parse the record grammar.
On the other hand, the pax format is both more space efficient and vastly more flexible.
In any case, the result is that a tar extractor which wants to support both pax tar files
and GNU tar files needs to support 5 different ways of reading the file path,
5 different ways of reading the link path,
and 3 different ways of reading the file size.
Whatever happened to the nice and simple format we started out with?
Why GNU tar extracts in quadratic time
Our simple tar extraction implementation has what could be considered a quite serious security bug:
It allows people to put files outside the directory we're extracting to.
Nothing is stopping an evil arcive from containing a file object with file_path="../hello.txt".
You might try to fix that by just disallowing file objects from using ".." as a path component,
but it's not that simple.
Consider the following sequence of file objects:
Symlink, file_path="./foo", link_path=".."
Normal file, file_path="./foo/hello.txt"
We want to allow symlinks which point to their parent directory, since there are completely legitimate
use cases for that.
We could try to figure out whether a symlink will end up pointing to somewhere outside of the
extraction directory, but that gets complicated real fast when you have to consider symlinks
to symlinks and hard links to symlinks.
It might be possible to do correctly, but it's not the solution GNU tar goes for.
When GNU tar encounters a hard link or symlink with ".." as a path component in its link_path,
tar will create a regular file in its place as a placeholder, and put a note about the delayed link
in a linked list datastructure.
When it's done extracting the entire archive, it will go through the whole list of delayed links
and replace the placeholders with proper links.
So far, so good.
The problem comes when trying to extract a hard link which doesn't contain ".." as a path component
in its link_path.
GNU tar wants to create such hard links immediately if it can.
But it can't create a hard link if the target is occupied by a placeholder file.
That means, every time GNU tar wants to create a hard link, it first has to walk the entire linked list
of delayed links and see if the target is a delayed link.
If the target is a delayed link, the new link must also be delayed.
Your time complexity alarm bells should be starting to ring now.
For every hard link, we walk the list of all delayed links.
But it actually gets worse; for reasons I don't quite understand yet, tar will actually go through
the entire list of delayed links again if it found out that it can create the link immediately.
So for all "normal" hard links, it has to go through the entire linked list of delayed links twice.
If you're a bit crafty, you can construct a tar archive which GNU tar extracts in precisely O(n^2) time;
you just need to alternate between links whose link_path has ".." as a path component
and thus get delayed, and "normal" hard links which don't get delayed.
If you're a bit unlucky, you might have a totally benign tarball which nevertheless happens to contain
a bunch of symlinks which refer to files in a parent directory, followed by a bunch of normal hard links.
This is what had happened to me.
My tarball happened to contain over 800 000 links with ".." as a path component.
It also happened to contain over 5.4 million hard links.
Every one of those hard links had to go through the entire list of every hitherto deferred link.
No wonder tar got slow.
If you ever find yourself in this situation, pass the --absolute-paths (or -P) parameter to tar.
Tar's documentation says this about --absolute-paths:
Preserve pathnames. By default, absolute pathnames (those that begin with a /
character) have the leading slash removed both when creating archives and extracting
from them. Also, tar will refuse to extract archive entries whose pathnames contain ..
or whose target directory would be altered by a symlink. This option suppresses these
behaviors.
You would never guess it from reading the documentation, but when you pass --absolute-paths
during extraction,
tar assumes that the archive is benign and the whole delayed linking mechanism is disabled.
Make sure you trust the tar archive though! When extracted with --absolute-paths,
a malicious archive will be able to put files anywhere it wants.
I'm absolutely certain that it's possible to make GNU tar extract in O(n) without --absolute-paths
by replacing the linked list with a hash map.
But that's an adventure for another time.
References
These are the documents I've drawn information from when researching for my tar extractor
and this blog post:
It's really common to want to embed some static data into a binary.
Game developers want to embed their shaders. Developers of graphical apps may
want to embed sounds or icons. Developers of programming language interpreters
may want to embed their language's standard library. I have many times built
software whose GUI is in the form of a web app served from a built-in HTTP server,
where I want to embed the HTML/JS/CSS into the binary.
Since neither C nor C++ currently has a built-in way to embed files,
we use work-arounds. These usually fall into one of two categories:
Either we use toolchain-specific features to generate object files with the data
exposed as symbols, or we generate
C code which we subsequently compile to object files. Since the toolchain-specific
features are, well, toolchain-specific, people writing cross-platform software
generally prefer code generation.
The most common tool I'm aware of to generate C code for embedding data is xxd,
whose -i option will generate C code with an unsigned char array literal.
Given the following input text:
<html>
<head>
<title>Hello World</title>
</head>
<body>
Hello World
</body>
</html>
index.html
The command xxd -i index.html will produce this C code:
This works fairly well. Any C or C++ compiler can compile that code and produce
an object file with our static data, which we can link against to embed that data
into our binary. All in a cross-platform and cross-toolchain way.
There's just one problem: It's slow. Really slow. On my laptop,
embedding a megabyte this way takes 2 seconds using g++. Embedding one decent
quality MP3 at 8.4MB takes 23 seconds, using 2.5 gigabytes of RAM.
bippety-boppety.mp3, an 8.4MB song
Whether or not we should embed files of that size into our binaries
is a question I won't cover in this article, and the answer depends a lot on context.
Regardless, processing data at just over 400kB per second is objectively terrible.
We can do so much better.
The main reason it's so slow is that parsing arbitrary C++ expressions is actually
really complicated. Every single byte is a separate expression,
parsed using a complex general expression parser, presumably
separately allocated as its own node in the syntax tree. If only we could
generate code which combines lots of bytes of data into one token...
I wrote a small tool, called strliteral,
which outputs data as a string literal rather than a character array.
The command strliteral index.html will produce this C code:
It should come as no surprise that this is many times faster to parse than the
character array approach. Instead of invoking a full expression parser
for each and every byte, most of the time will just be spent in a tight loop
which reads bytes and appends them to an array. The grammar for a string literal
is ridiculously simple compared to the grammar for an array literal.
Compared to xxd's 23 seconds and 2.5GB of RAM usage for my 8.4MB file,
my strliteral tool produces code which g++ can compile in 0.6 seconds, using only
138 megs of RAM. That's almost a 40x speed-up, and an 18x reduction in RAM usage.
It's processing data at a rate of 15MB per second, compared to xxd's
0.4MB per second. As a bonus, my tool generates 26MB of C code, compared to
xxd's 52MB.
Here's how that song looks, encoded with strliteral:
The difference is even bigger when processing mostly-ASCII text rather than
binary data. Since xxd produces the same 6 bytes of source code for every byte of
input (0x, two hex digits, comma, space), the data itself doesn't matter.
However, strliteral produces 4 bytes of source code (\, then three octal digits)
for every "weird" character, but just one byte of source code for every
"regular" ASCII character.
Graphs
I wrote some benchmarking code to compare various aspects of xxd and
strliteral. All times are measured using an Intel Core i7-8705G CPU in a
Dell XPS 15 9575. g++ and xxd are from the Ubuntu 20.04 repositories.
strliteral is compiled with gcc -O3 -o strliteral strliteral.c using GCC 9.3.0.
The benchmarking source code can be found here:
https://github.com/mortie/strliteral/tree/master/benchmark
Here's a graph which shows exactly how the two tools
compare, across a range of input sizes, given either text or random binary data:
The 70x number in the title comes from this graph. The 60ms spent
compiling strliteral-generated code is 72x faster than the 4324ms spent
compiling xxd-generated code. Comparing random binary data instead of text
would show a lower - though still respectable - speed-up of 25x.
Though most of the time spent when embedding data with xxd comes from the compiler,
the xxd tool itself is actually fairly slow too:
Those ~200 milliseconds xxd takes to generate code for a 2MB file isn't very
significant compared to the 4.3 second compile time, but if strliteral was
equally slow, 75% of the time would've been spent generating code as opposed
to compiling code. Luckily, strliteral runs through 2MB of text in 11ms.
Looking at the xxd source code,
the reason it's so slow seems to be that it prints every single byte using a call
to fprintf:
while ((length < 0 || p < length) && (c = getc(fp)) != EOF)
{
if (fprintf(fpo, (hexx == hexxa) ? "%s0x%02x" : "%s0X%02X",
(p % cols) ? ", " : &",\n "[2*!p], c) < 0)
die(3);
p++;
}
Finally, here's a graph over g++'s memory usage:
Caveats
Update: In the reddit discussion,
someone pointed out that MSVC, Microsoft's compiler, has a fairly low maximum
string length limit (the exact limit is fairly complicated).
I had assumed that any modern compiler would just keep strings in a variable sized
array. Maybe strliteral will eventually grow an MSVC-specific workaround,
but until then, using a better compiler like Clang or GCC on Windows is an option.
Using string literals for arbitrary binary data is a bit more complicated than
using an array with integer literals.
Both xxd and strliteral might have trouble in certain edge cases,
such as when cross-compiling if the host and target disagrees on the number
of bits in a byte. Using string literals adds an extra complication due to the
distinction between the "source character set" and the "execution character set".
The C11 spec (5.2.1p2) states:
In a character constant or string literal, members of the execution character
set shall be represented by corresponding members of the source character set
or by escape sequences consisting of the backslash \
followed by one or more characters.
If you run strliteral on a file which contains the byte 97, it will output the
code const unsigned char data[] = "a";. If that C code is compiled with a
"source character set" of ASCII and an "execution character set" of EBCDIC,
my understanding of the standard text is that the ASCII "a" (byte 97)
will be translated to the EBCDIC "a" (byte 129). Whether that's even a bug
or not depends on whether the intention is to embed binary data or textual data,
but it's probably not what people expect from a tool to embed files.
This should only ever become an issue if you're compiling with different
source and execution charsets, where the source charset and execution charset
aren't based on ASCII. Compiling with a UTF-8 source charset and an EBCDIC
execution charset will cause issues, but since all non-ASCII characters are printed
as octal escape sequences, compiling with e.g a UTF-8 source charset and a
LATIN-1 execution charset isn't an issue.
It seems extremely unlikely to me that someone will compile with a source charset
and an execution charset which are both different and not based on ASCII,
but I suppose it's something to keep in mind. If it does become an issue,
the --always-escape option will cause strliteral to only generate octal escape
sequences. That should work the same as xxd -i in all cases, just faster.
Some implementation notes
C is a weird language. For some reason, probably to better support systems
where bytes are bigger than 8 bits, hex string escapes like "\x6c" can be an
arbitrary number of characters. "\xfffff" represents a string with one character
whose numeric value is 1048575. That obviously won't work on machines with 8-bit bytes,
but it could conceivably be useful on a machine with 24-bit bytes, so it's allowed.
Luckily, octal escapes are at most 3 numbers, so while "\xf8ash" won't work,
"\370ash" will.
C also has a concept of trigraphs and digraphs, and they're expanded even within
string literals. The string literals "??(" and "[" are identical (at least
in C, and in C++ before C++17). Currently, strliteral just treats ?, : and
% as "special" characters which are escaped, which means no digraphs or trigraphs
will ever appear in the generated source code. I decided it's not worth the effort
to add more "clever" logic which e.g escapes a ( if the two preceeding characters
are question marks.
I happen to think that the current lambda syntax for C++ is kind of verbose.
I'm not the only one to have thought that, and there has already been a paper
discussing a possible abbreviated lambda syntax
(though it was rejected).
In this blog post, I will detail my attempt to implement a sort of simplest possible
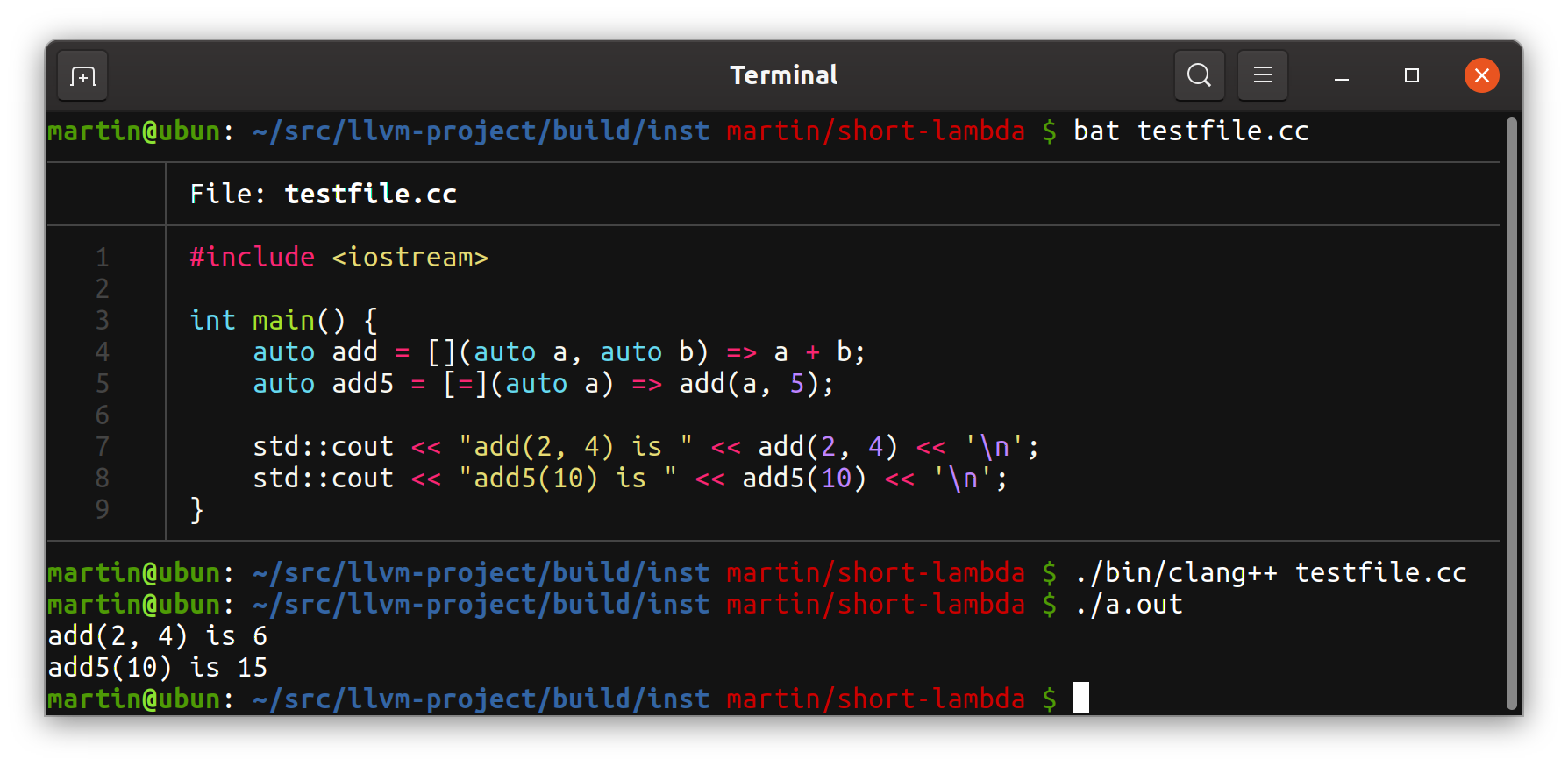
version of an abbreviated lambda syntax. Basically, this:
[](auto &&a, auto &&b) => a.id() < b.id();
should mean precisely:
[](auto &&a, auto &&b) { return a.id() < b.id(); };
I will leave a discussion about whether that change is worth it or not
to the end. Most of this article will just assume that we want that new syntax,
and discuss how to actually implement it in Clang.
git clone https://github.com/llvm/llvm-project.git
cd llvm-project && mkdir build && cd build
cmake -DCMAKE_INSTALL_PREFIX=`pwd`/inst -DLLVM_ENABLE_PROJECTS=clang -DCMAKE_BUILD_TYPE=Release ../llvm
make -j 8
make install
A few points to note:
The build will take a long time. Clang is big.
I prefer -DCMAKE_BUILD_TYPE=Release because it's way faster to build.
Linking Clang with debug symbols and everything takes ages and
will OOM your machine.
This will install your built clang to inst (short for "install").
The clang binary itself will be in inst/bin/clang.
Now that we have a clang setup, we can have a look at how the project is
laid out, and play with it.
Changing the Clang code
The feature I want to add is very simple: Basically, I want [] => 10 to mean
the exact same thing as [] { return 10; }. In order to understand how one
would achieve that, an extremely short introduction to how compilers work
is necessary:
Our code is just a sequence of bytes, like [] => 10 + 20. In order for Clang to
make sense of that, it will go through many steps. We can basically divide
a compiler into two parts: the "front-end", which goes through many steps to
build a thorough understanding of the code as a
tree structure, and the "back-end"
which goes through many steps to remove information, eventually ending up with
a simple series of bytes again, but this time as machine code instead of ASCII.
We'll ignore the back-end for now. The front-end basically works like this:
Split the stream of bytes into a stream of tokens. This step turns [] => 10 + 20
into something like (open-bracket) (close-bracket) (fat-arrow) (number: 10) (plus) (number: 20).
Go through those tokens and construct a tree. This step turns the sequence of tokens
into a tree: (lambda-expression (body (return-statement (add-expression (number 10) (number 20)))))
(Yeah, this looks a lot like Lisp. There's a reason people say Lisp basically
has no syntax; you're just writing out the syntax tree by hand.)
Add semantic information, such as types.
The first phase is usually called lexical analysis, or tokenization, or scanning.
The second phase is what we call parsing. The third phase is usually called
semantic analysis or type checking.
Well, the change I want to make involves adding a new token, the "fat arrow" token =>.
That means we'll have to find out how the lexer (or tokenizer) is implemented;
where it keeps its list of valid tokens types, and where it turns the input text
into tokens.
After some grepping, I found the file
clang/include/clang/Basic/TokenKinds.def,
which includes a bunch of token descriptions, such as
PUNCTUATOR(arrow, "->"). This file seems to be a
"supermacro";
a file which exists to be included by another file as a form of macro expansion.
I added PUNCTUATOR(fatarrow, "=>") right below the PUNCTUATOR(arrow, "->") line.
Now that we have defined our token, we need to get the lexer to actually
generate it.
After some more grepping, I found
clang/lib/Lex/Lexer.cpp,
where the Lexer::LexTokenInternal function is what's actually looking at
characters and deciding what tokens they represent. It has a case statement
to deal with tokens which start with an = character:
case '=':
Char = getCharAndSize(CurPtr, SizeTmp);
if (Char == '=') {
// If this is '====' and we're in a conflict marker, ignore it.
if (CurPtr[1] == '=' && HandleEndOfConflictMarker(CurPtr-1))
goto LexNextToken;
Kind = tok::equalequal;
CurPtr = ConsumeChar(CurPtr, SizeTmp, Result);
} else {
Kind = tok::equal;
}
break;
Given that, the change to support my fatarrow token is really simple:
case '=':
Char = getCharAndSize(CurPtr, SizeTmp);
if (Char == '=') {
// If this is '====' and we're in a conflict marker, ignore it.
if (CurPtr[1] == '=' && HandleEndOfConflictMarker(CurPtr-1))
goto LexNextToken;
Kind = tok::equalequal;
CurPtr = ConsumeChar(CurPtr, SizeTmp, Result);
// If the first character is a '=', and it's followed by a '>', it's a fat arrow
} else if (Char == '>') {
Kind = tok::fatarrow;
CurPtr = ConsumeChar(CurPtr, SizeTmp, Result);
} else {
Kind = tok::equal;
}
break;
Now that we have a lexer which generates a tok::fatarrow any time it encounters
a => in our code, we can start changing the parser to make use of it.
Since I want to change lambda parsing, the code which parses a lamba seems like
a good place to start (duh). I found that in a file called
clang/lib/Parse/ParseExprCXX.cpp,
in the function ParseLambdaExpressionAfterIntroducer. Most of the function deals
with things like the template parameter list and trailing return type,
which I don't want to change, but the very end of the function contains this gem:
Parse a compound statement body (i.e consume a {, read statements until the }).
After some housekeeping, act on the now fully parsed lambda expression.
In principle, what we want to do is to check if the next token is a => instead
of a {; if it is, we want to parse an expression instead of a compound statement,
and then somehow pretend that the expression is a return statement.
Through some trial, error and careful copy/pasting, I came up with this block
of code which I put right before the if (!Tok.is(tok::l_brace)):
// If this is an arrow lambda, we just need to parse an expression.
// We parse the expression, then put that expression in a return statement,
// and use that return statement as our body.
if (Tok.is(tok::fatarrow)) {
SourceLocation ReturnLoc(ConsumeToken());
ExprResult Expr(ParseExpression());
if (Expr.isInvalid()) {
Actions.ActOnLambdaError(LambdaBeginLoc, getCurScope());
return ExprError();
}
StmtResult Stmt = Actions.ActOnReturnStmt(ReturnLoc, Expr.get(), getCurScope());
BodyScope.Exit();
TemplateParamScope.Exit();
if (!Stmt.isInvalid() && !TrailingReturnType.isInvalid())
return Actions.ActOnLambdaExpr(LambdaBeginLoc, Stmt.get(), getCurScope());
Actions.ActOnLambdaError(LambdaBeginLoc, getCurScope());
return ExprError();
}
// Otherwise, just parse a compound statement as usual.
if (!Tok.is(tok::l_brace)) ...
This is really basic; if the token is a => instead of a {, parse an expression,
then put that expression into a return statement, and then use that return statement
as our lambda's body.
And it works! Lambda expressions with fat arrows are now successfully parsed
as if they were regular lambdas whose body is a single return statement:
Was it worth it?
Implementing this feature into Clang was definitely worth it just to get more
familiar with how the code base works. However, is the feature itself
a good idea at all?
I think the best way to decide if a new syntax is better or not is to look at
old code which could've made use of the new syntax, and decide if the new
syntax makes a big difference.
Therefore, and now that I have a working compiler, I have gone through all the
single-expression lambdas and replaced them with my fancy new arrow lambdas in
some projects I'm working on.
This code deletes a chunk from a game world if the chunk isn't currently active.
In my opinion, the version with the arrow function is a bit clearer,
but a better solution could be C++17's std::invoke. If I understand std::invoke
correctly, if C++ was to adopt std::invoke for algorithms, this code could
be written like this:
This looks nicer, but has the disadvantage that you need to add an extra method
to the class. Having both isActive and its negation isInactive as member functions
just because someone might want to use it as a predicate
in an algorithm sounds unfortunate. I prefer lambdas' fleixibilty.
This code maps a vector of unique pointers to raw pointers.
This is yet another case where I think the arrow syntax is slightly nicer than
the C++11 alternative, but this time, we could actually use the member function
invocation if I changed my map function to use std::invoke:
Well, this illustrates that invoking a member function doesn't really work with
overly complex types. Imagine if the type was instead something more elaborate:
The behavior of a C++ program is unspecified (possibly ill-formed)
if it explicitly or implicitly attempts to form a pointer, reference
(for free functions and static member functions) or pointer-to-member
(for non-static member functions) to a standard library function
or an instantiation of a standard library function template,
unless it is designated an addressable function.
Again, the short lambda version looks a bit better to me. However, here again,
we could replace the lambda with a member reference if algorithms were
changed to use std::invoke:
Overall, I see a short lambda syntax as a modest improvement.
The biggest readability win mostly stems from the lack of that awkward
; }); at the end of an expression; foo([] => bar()) instead of
foo([] { return bar(); });. It certainly breaks down a bit when
the argument list is long; neither of these two lines are particularly short:
foo([](auto const &&a, auto const &&b, auto const &&c) => a + b + c);
foo([](auto const &&a, auto const &&b, auto const &&c) { return a + b + c; });
I think, considering the minimal cost of implementing this short lambda syntax,
the modest improvements outweigh the added complexity. However, there's also an
opportunity cost associated with my version of the short lambda syntax:
it makes a better, future short lambda syntax either impossible or
more challenging. For example, accepting my syntax would mean we couldn't really
adopt a ratified version of
P0573R2's
short lambda syntax in the future, even if
the issues with it
were otherwise fixed.
Therefore, I will argue strongly that my syntax makes code easier to read,
but I can't say anything about whether it should be standardized or not.
Aside: Corner cases
If we were to standardize this syntax, we would have to consider all kinds of
corner cases, not just accept what clang with my changes happens to to do.
However, I'm still curious about what exactly clang happens to do with my changes.
How does this interact with the comma operator?
The comma operator in C++ (and most C-based languages) is kind of strange.
For example, what does foo(a, b) do? We know it calls foo with the arguments
a and b, but you could technically decide to parse it as foo(a.operator,(b)).
My arrow syntax parses foo([] => 10, 20) as calling foo with one argument;
a function with the body 10, 20 (where the comma operator means the 10
does nothing, and 20 is returned). I would probably want that to be changed,
so that foo is called with two arguments; a lambda and an int.
This turns out to be fairly easy to fix, because Clang already has ways of
dealing with expressions which can't include top-level commas.
After all, there's precedence here; since clang parses foo(10, 20) without
interpreting the , a top-level comma as a comma operator, we can use the same
infrastructure for arrow lambdas.
Parse an expr that doesn't include (top-level) commas.
Calling ParseAssignmentExpression is also the first thing the ParseExpression
function does. It seems like it's just the general function for parsing an
expression without a top-level comma operator, even though the name is
somewhat misleading. This patch changes arrow lambdas to use
ParseAssignmentExpression instead of ParseExpression:
https://github.com/mortie/llvm/commit/c653318c0056d06a512dfce0799b66032edbed4c
How do immediately invoked lambdas work?
With C++11 lambdas, you can write an immediately invoked lambda in the obvious
way; just do [] { return 10; }(), and that expression will return 10.
With my arrow lambda syntax, it's not quite as obvious. Would [] => foo() be
interpreted as immediately invoking the lambda [] => foo, or would it be
interpreted as creating a lambda whose body is foo()?
In my opinion, the only sane way for arrow lambdas to work would be that
[] => foo() creates a lambda with the body foo(), and that creating
an immediately invoked lambda would require extra parens; ([] => foo())().
That's also how my implementation happens to work.
How does this interact with with explicit return types, specifiers, etc?
Since literally all the code before the arrow/opening brace is shared
between arrow lambdas and C++11 lambdas, everything should work exactly the same.
That means that all of these statements should work:
auto l1 = []() -> long => 10;
auto l2 = [foo]() mutable => foo++;
auto l3 = [](auto a, auto b) noexcept(noexcept(a + b)) => a + b;
And so would any other combination of captures, template params, params,
specifiers, attributes, constraints, etc, except that the body has to be a
single expression.